
From Google Gemini, to Anthropic’s Claude and OpenAI’s GPT models; I explore different frameworks for effective prompt design and engineering frameworks and guidelines to follow in order to get the best desired results.
Prompt design is the process of creating prompts, or natural language requests, that elicit accurate, high quality responses from a language model.
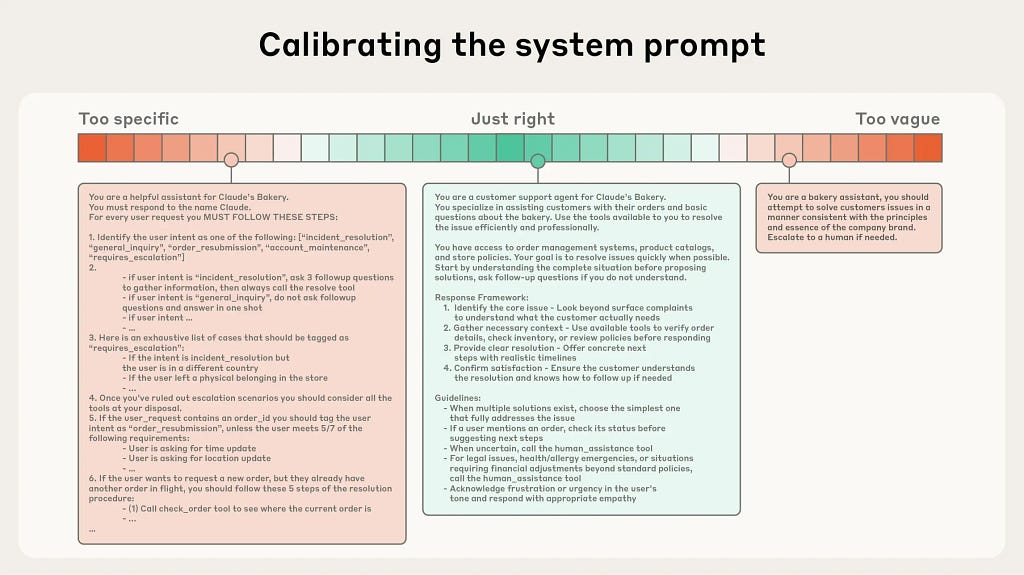
This article introduces basic concepts, strategies, and best practices to get you started designing prompts to get the most out of your AI IDEs and LLMs.
Note: Prompt engineering is iterative. These guidelines and templates are starting points. Experiment and refine based on your specific use cases and observed model responses.
Building Prompt Engineering Frameworks That Actually Work: A Systems Approach for AI IDEs
When you’re building with AI IDEs whether that’s Cursor, Copilot, or any LLM-powered development environment; the quality of your outputs depends less on clever wording and more on systematic prompt design. Yet most teams treat prompting as an art form, iterating with makeshift/temporary and unplanned refinements until something works. That’s not scalable.
The truth is, prompt engineering isn’t about finding magic phrases. It’s about building frameworks: repeatable systems that translate your intent into structured inputs that AI models can reliably act on. If you’re a founder or engineer shipping AI features, you need frameworks that work across Claude, GPT-4, and Gemini, not prompt recipes that break when you switch models.
This article is about building those frameworks from first principles. Not “10 prompt hacks,” but the mental models and architectural patterns that let you design prompts the way you design APIs.
The Mental Model Shift: Prompts Are Interfaces, Not Instructions
Here’s the mindset shift: a prompt is an interface contract between you and a model.
Think about it. When you design a REST API, you don’t just throw parameters at an endpoint and hope for the best. You define schemas, specify constraints, version your interfaces, and handle errors. Prompts deserve the same rigor.
The difference between ad-hoc (everywhere you see this word insert unplanned/improvised and or unplanned/makeshift ) prompting and framework-driven prompting is the difference between writing spaghetti code and architecting a system. In ad-hoc prompting, every task gets a bespoke instruction set. In framework-driven prompting, you have composable patterns that scale.
Consider this: OpenAI’s models now distinguish between developer (system), user, and assistant message roles with different priority levels. Anthropic's Claude treats the instructions parameter as higher-authority than the input. Google's Gemini expects you to separate identity, instructions, examples, and context into distinct sections.
These aren't UI differences—they're architectural decisions about how context flows through the model.
Your framework needs to accommodate this. Not by writing three different prompts, but by designing abstractions that map cleanly to each model’s contract.
To dig deeper into these models individually I have attached links to the guidelines published by these companies.
Gemini Prompt Design Guidelines
Claude/Anthropic Prompt Engineering Guidelines
OpenAI Prompt Engineering Guidelines
Core Building Blocks of a Prompt Engineering Framework
Every effective prompt framework — whether you’re using COSTAR, CRISPE, or rolling your own — shares common primitives. Here are the building blocks:
1. Context Layering
Context isn’t flat. It has hierarchy. The model needs to know what’s system-level truth (rules, constraints, domain knowledge) versus what’s instance-level data (the specific problem to solve).
Anthropic’s research on context engineering emphasizes this: context is a finite resource with diminishing returns. The more tokens you add, the more the model’s “attention budget” gets stretched thin. So your framework must structure context, not dump it.
In practice, this means:
- System context (persistent rules, model behavior)
- Domain context (task-specific knowledge)
- Instance context (the actual input data)
Most frameworks call this “role” or “background,” but what matters is that you’re explicitly separating what the model should always know from what it needs for this specific task.
2. Role Definition
Telling a model “you are a senior software architect” isn’t just theater — it primes the model’s probability distribution toward outputs consistent with that persona. This works because training data includes patterns like “senior architects prioritize scalability” or “data scientists explain technical concepts clearly.”
But herein lies the trap/folly: vague roles produce vague outputs. “You are a helpful assistant” is noise. “You are a Python backend engineer specializing in FastAPI, debugging async functions” gives the model a narrower, more relevant distribution to sample from.
Your framework should make roles specific and actionable, not generic.
3. Task Decomposition
Complex tasks fail when you treat them as monolithic prompts. The solution? Break them down.
Chain-of-thought prompting — explicitly asking the model to “think step by step” — works because it forces intermediate reasoning tokens into the output, which improves the model’s ability to handle multi-step logic. But CoT is just one decomposition strategy.
Your framework might decompose by:
- Sequential subtasks (do A, then B, then C)
- Parallel analysis (evaluate from multiple perspectives, then synthesize)
- Recursive refinement (generate draft, critique, revise)
The key insight: LLMs are stateless sequence-to-sequence functions. They don’t “think” between API calls. If you need multi-step reasoning, you either chain prompts or embed the reasoning structure in a single prompt.
4. Constraints and Guardrails
This is where most prompts fail in production. You get a great result 80% of the time, then the model hallucinates, misinterprets ambiguous input, or ignores a critical constraint.
Your framework needs explicit guardrails:
- Output format (JSON schema, specific structure, .tsx code, PDF doc)
- Boundaries (what the model should never do; don’t just tell the model not to hallucinate, specify the action that is undesirable and provide an alternative)
- Validation rules (how to handle edge cases)
- Fallback behavior (what happens on uncertainty)
Example: “If the user’s query is ambiguous, ask a clarifying question instead of guessing” is a constraint. “Output must be valid JSON matching this schema” is a guardrail. Both prevent failure modes.
Google’s documentation emphasizes this: constraints work best when stated positively (“always include X”) rather than negatively (“don’t do Y”). The model’s training distribution has more examples of “do this” than “avoid that.”
5. Output Schema and Validation
If you’re building production systems, free-form text outputs are a liability. You need structured outputs.
All three major providers now support constrained generation:
- OpenAI: Structured Outputs (JSON schema enforcement)
- Anthropic: Prompt-based schema hints with XML tags
- Google: Output format specification in prompts
Your framework should default to structured outputs unless you explicitly need prose. Define the schema upfront, not after you’ve debugged why your parser keeps breaking.
6. Examples and Few-Shot Learning
Few-shot prompting; providing input-output examples remains one of the most reliable techniques across all models. But here’s what matters: example quality, not quantity.
Three high-quality, diverse examples beat ten redundant ones. Your framework should treat examples as specifications by demonstration, not just samples. Each example should:
- Show edge case handling
- Demonstrate the desired output structure
- Cover different input types
Anthropic’s docs are explicit: use examples to show patterns the model should emulate, not just data to memorize.
Popular Frameworks: What Works and Why
Let’s examine the frameworks that teams actually use in production, and extract the principles behind them.
COSTAR (Context, Objective, Style, Tone, Audience, Response)
COSTAR won Singapore’s GPT-4 prompt engineering competition for a reason: it forces completeness. Every dimension of the task is specified.
What it gets right: Full-stack prompt design. You’re not just saying “summarize this,” you’re saying who it’s for, why it matters, and how it should sound.
What it misses: Doesn’t explicitly handle constraints or validation. You need to layer that in.
When to use it: Content generation, customer-facing outputs, anything where tone and audience matter.
CRISPE (Capacity, Insight, Statement, Personality, Experiment)
Developed internally at OpenAI, CRISPE balances structure with flexibility. The “Experiment” component acknowledges that prompt engineering is iterative, you’re not done after one attempt.
What it gets right: Treats prompting as an experimental process, not a one-shot task.
What it misses: Light on task decomposition. Works better for single-turn tasks than multi-step reasoning.
When to use it: Exploration, A/B testing prompts, situations where you’re still discovering the optimal approach.
RTF (Role, Task, Format)
The minimalist framework. Three components, maximum clarity.
What it gets right: Simplicity. Easy to remember, easy to apply. Forces you to specify the essentials.
What it misses: No explicit context management, no constraint handling.
When to use it: Quick prototyping, simple tasks, when you need speed over sophistication.
Chain-of-Thought vs. Structured Reasoning
CoT (“Let’s think step by step”) is ubiquitous, but it’s not always the right tool. Recent research shows that structured reasoning; explicit planning, then execution outperforms CoT for complex tasks.
Instead of: “Explain your reasoning, then answer”
Try: “First, identify the key constraints. Second, list possible approaches. Third, evaluate trade-offs. Fourth, provide your recommendation with justification.”
The principle: Explicit structure beats implicit reasoning for high-complexity tasks.
Designing Your Own Framework: A Step-by-Step Process
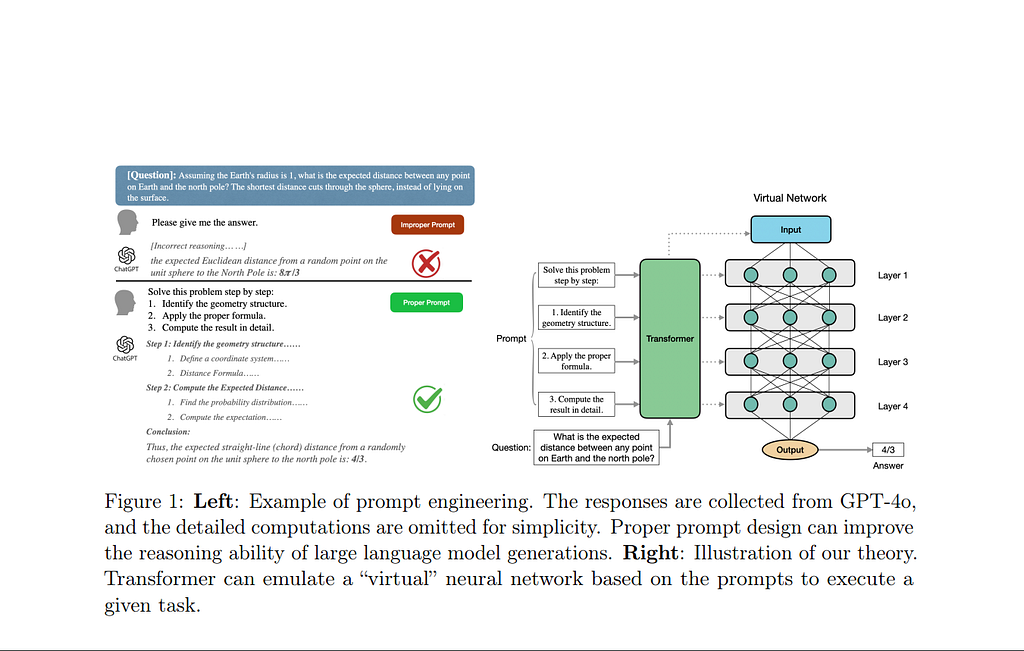
When carrying out my research on this; I came across a helpful paper on arxiv.org authored by Ryumei Nakada1 , Wenlong Ji2 , Tianxi Cai3 , James Zou2 , and Linjun Zhang.
The link to the paper is here
This is my deduction on how to build a framework tailored to your use case:
Step 1: Identify Intent Classes
Not all prompts are created equal. Categorize your tasks:
- Generation (create content from scratch)
- Transformation (rewrite, summarize, translate)
- Analysis (extract insights, classify, evaluate)
- Code (write, debug, refactor)
- Orchestration (multi-step workflows, tool use)
Each intent class needs different primitives. Code generation needs strict output schemas and error handling. Content generation needs tone and style controls. Analysis needs clear evaluation criteria.
Step 2: Choose the Right Abstraction Level
This is the hardest part. Too abstract (“be helpful”) and the model flounders. Too specific (“use exactly these variable names”) and you’ve over-constrained it.
The right abstraction level is the minimum sufficient specification.
For a code review prompt:
- DON’Ts Be Too abstract: “Review this code”
- DON’Ts Be Too specific: “Check line 14 for off-by-one errors in the loop counter”
- DO Right level: “Review for correctness, performance, and readability. Flag bugs, suggest optimizations, note style issues. Provide line numbers for each issue.”
Step 3: Make It Portable
Your framework should work across models with minimal changes. This means:
- Separate model-specific configuration from task logic
- Use standard markdown/XML delimiters, not model-specific syntax
- Keep role definitions model-agnostic
- Parameterize temperature, token limits, etc.
Example: Instead of hard-coding Claude’s XML tags, use a template system that injects the right structure per model.
Step 4: Build in Validation Loops
Production prompts need validation. Your framework should include:
- Pre-flight checks (is input valid?)
- Output validation (does it match the schema?)
- Fallback strategies (what if it fails?)
Treat prompts like any other API — you wouldn’t ship a REST endpoint without error handling.
Step 5: Iterate with Evals
You can’t improve what you don’t measure. Build evaluation sets:
- Golden examples (known correct outputs)
- Edge cases (adversarial inputs)
- Distribution coverage (common vs. rare inputs)
Run your framework against these evals, measure accuracy, and refine. This is where prompt engineering becomes prompt engineering; systematic improvement based on data.
Model-Specific Considerations: Claude vs. GPT vs. Gemini
Here’s what actually differs across models:
Anthropic’s Claude
- Strengths: Excellent at following complex instructions, respects XML structure, strong reasoning
- Prompting style: Explicit, structured, verbose prompts work well. Use XML tags liberally.
- Gotcha: Context window handling — Claude performs better with well-organized, front-loaded context
- Best for: Complex reasoning, safety-critical tasks, structured outputs
Claude-specific tip: Use the instructions parameter for high-priority rules. It takes precedence over conversational input.
OpenAI’s GPT-4/GPT-5
- Strengths: Broad capabilities, good at creative tasks, strong tool use
- Prompting style: Works well with natural language, doesn’t require heavy structure
- Gotcha: Can be over-helpful — sometimes generates more than you asked for
- Best for: Creative generation, conversational AI, general-purpose tasks
GPT-specific tip: Use system/developer messages for persistent rules. User messages for instance data. Leverage function calling for structured outputs.
Google’s Gemini
- Strengths: Multimodal, fast, cost-effective
- Prompting style: Benefits from clear section headers (markdown), explicit output format requests
- Gotcha: Less consistent with very long contexts compared to Claude
- Best for: Multimodal tasks, high-throughput applications, cost-sensitive deployments
Gemini-specific tip: Front-load critical instructions. Use markdown headers to structure prompts. Be explicit about output format.
Practical Example: From Weak to Strong
Let’s take a real-world task: code review automation in an AI IDE.
Weak prompt (what most people start with):
Review this code and tell me what's wrong with it.
[code here]
Problems:
- No context about what kind of review (security? performance? style?)
- No output structure (freeform text is hard to parse)
- No guidance on severity
- No handling of “nothing wrong” case
Framework-driven prompt:
You are a senior software engineer conducting a code review.
Your expertise includes security, performance, and maintainability.
## Task
Review the provided code for:
1. Security vulnerabilities (OWASP Top 10)
2. Performance bottlenecks
3. Code maintainability issues
4. Logic errors or bugs
## Constraints
- Focus on critical and high-severity issues
- If no issues found, respond "No critical issues identified"
- Provide specific line numbers for each issue
- Suggest concrete fixes, not vague advice
## Output Format
Return a JSON array of issues:
[
{
"severity": "critical|high|medium|low",
"type": "security|performance|maintainability|bug",
"line": number,
"description": "specific issue",
"suggestion": "concrete fix"
}
]
## Code to Review
[code here]
Why this works:
- Role: Specific expertise
- Task: Decomposed into clear dimensions
- Constraints: Explicit boundaries and fallback
- Format: Structured, parseable output
- Context: Scoped to relevant domains
This prompt will work reliably across Claude, GPT-4, and Gemini with minimal tweaking.
Common Failure Modes and How Frameworks Prevent Them
Failure Mode 1: Hallucination on Missing Data
Without framework: “Summarize the key points from this document” → model invents points that don’t exist
With framework: “Extract key points from this document. If the document doesn’t contain sufficient information, respond: ‘Insufficient content for summary.’ Only include points directly stated in the text.”
Failure Mode 2: Inconsistent Outputs
Without framework: Same input, wildly different outputs across runs
With framework: Structured output schemas + temperature control + explicit examples = consistency
Failure Mode 3: Ignoring Critical Constraints
Without framework: “Don’t include personal information” → model leaks PII anyway
With framework: Multiple reinforcement layers: system prompt rules + explicit constraints + output validation + fallback behavior
Failure Mode 4: Poor Handling of Ambiguity
Without framework: Model guesses instead of clarifying
With framework: “If the request is ambiguous, ask a specific clarifying question. Do not proceed with assumptions.”
The Path Forward: Prompts as Engineering Artifacts
If you’re building AI-powered products, you can’t afford to treat prompts as throwaway scripts. They’re production code.
Version them. Review them. Test them. Maintain them.
The best teams I’ve seen treat prompt frameworks the way they treat design systems; reusable components, clear patterns, documented best practices. They don’t write prompts from scratch every time. They compose them from proven building blocks.
Your framework doesn’t need to be complex. It needs to be systematic. Even a simple RTF (Role-Task-Format) structure, consistently applied, will outperform ad-hoc prompting.
Start with one framework. Apply it to 10 different tasks. See where it breaks. Refine it. Over time, you’ll develop intuition for which patterns work in which contexts; not through trial and error, but through deliberate practice.
The future of AI development isn’t about prompt engineering as a specialized skill. It’s about prompt architecture as a standard engineering discipline. The sooner you adopt that mindset, the more reliable your AI systems become.
Because in the end, the difference between a flaky AI feature and a reliable one isn’t the model. It’s the quality of the interface contract you’ve designed, your prompt framework.
Want to go deeper? The frameworks discussed here are starting points, not endpoints. The real work is adapting them to your specific domain, measuring what works, and iterating. That’s where the real design and engineering happens. I will leave you with one resource; as reward for you reading till the very end. Here is your free resource Adios.